

Docker et CI/CD : comment automatiser vos déploiements web sans stress
En 2025, livrer vite n’est plus un luxe, c’est la norme. Les produits numériques évoluent par petites itérations, l’utilisateur attend des améliorations continues et les équipes ne tolèrent plus les nuits blanches de “mise en prod”. La compétitivité passe par une mécanique de livraison capable d’absorber ce rythme sans casser la qualité. C’est exactement ce que permettent Docker et les pipelines CI/CD lorsqu’ils sont abordés avec méthode : des environnements identiques du laptop à la production, des vérifications automatiques à chaque changement, et un déploiement piloté par des règles plutôt qu’à la main. L’automatisation devient alors un filet de sécurité tout autant qu’un accélérateur.
Continuer à déployer « à la main » en 2025 expose à des erreurs humaines coûteuses, à des délais imprévisibles et à des failles évitables dans la chaîne logicielle. L’industrialisation n’est pas réservée aux géants : elle est devenue une hygiène de base.
1. Docker : la fondation des déploiements modernes
Lorsque Docker a démocratisé la conteneurisation, il a surtout résolu un problème vieux comme le monde : l’écart entre « chez moi » et « en production ». Un conteneur embarque exactement ce qu’il faut pour exécuter l’application — ni plus, ni moins — et peut être reproduit à l’identique sur n’importe quel hôte compatible. Cette portabilité change tout pour les équipes : on casse moins, on livre plus souvent et on gagne en prévisibilité.
Les machines virtuelles gardent leur intérêt pour isoler des OS complets ou des charges très spécifiques. Mais pour le web, le différentiel est net. Une VM consomme classiquement des gigaoctets de RAM et met plusieurs dizaines de secondes à démarrer ; un conteneur s’initialise en quelques secondes avec une empreinte mémoire minuscule. La densité par serveur augmente et les coûts suivent la même courbe.
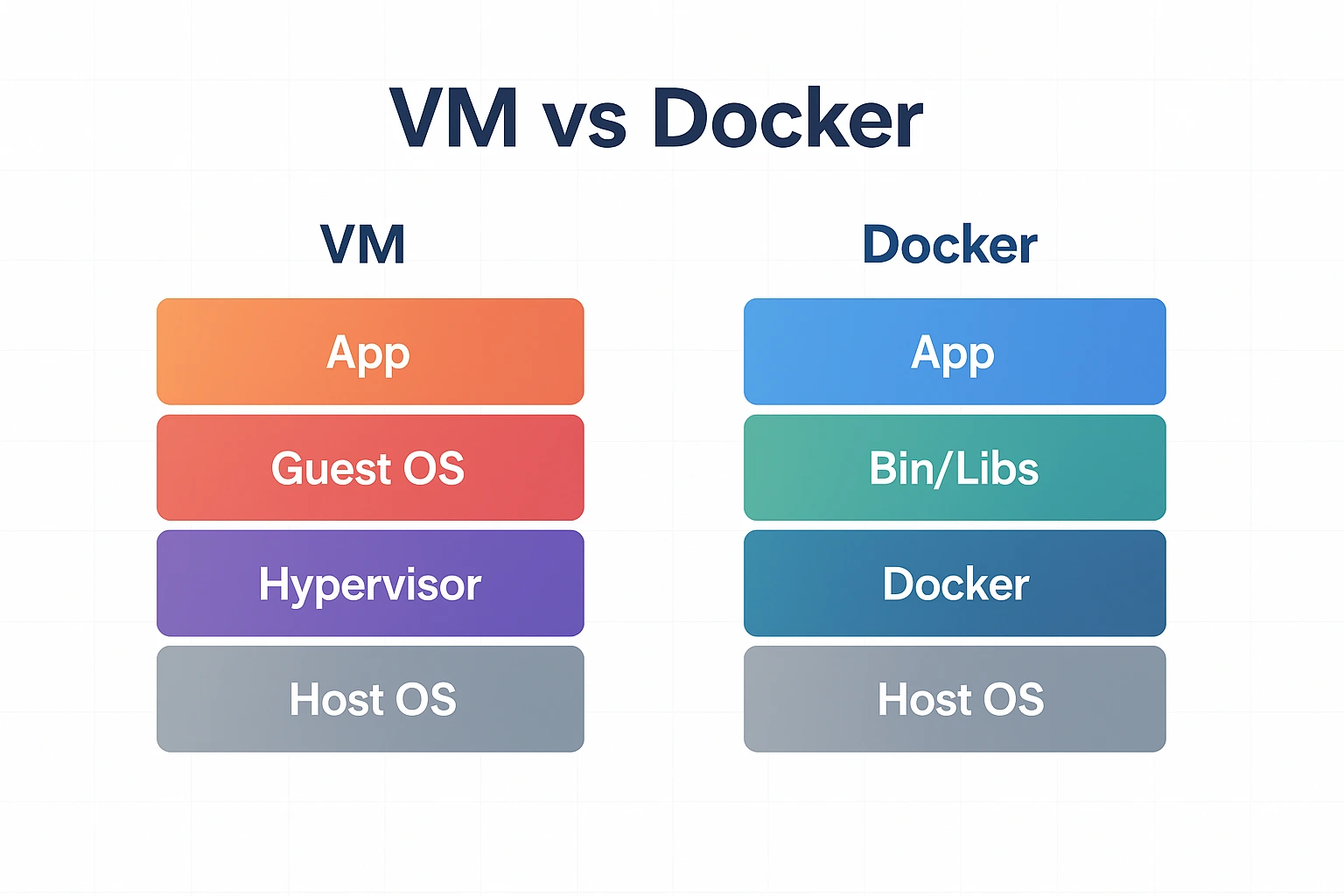
Kubernetes s’inscrit naturellement dans cette histoire. Docker s’occupe de fabriquer et d’exécuter l’unité de base, le conteneur. Kubernetes orchestre la flotte : il programme où les conteneurs tournent, les redémarre en cas d’incident, distribue la charge, met à jour progressivement les versions et expose des points de service stables au reste du système. On peut démarrer sans Kubernetes lorsque l’architecture et l’équipe sont modestes ; on y passe dès qu’il faut scaller, garantir un redémarrage automatique et déployer sans interruption.
Pensez Docker comme l’outil qui rend vos applications portables et reproductibles. Pensez Kubernetes comme la couche qui les rend hautes-disponibles et élastiques.
Sur le plan pratique, la maturité de l’écosystème facilite désormais la vie au quotidien. Les builds multi-stage allègent les images en séparant compilation et exécution. BuildKit apporte un cache fin qui évite de tout reconstruire à chaque commit. Les images peuvent être analysées automatiquement pour détecter les vulnérabilités et publiées avec une signature cryptographique afin d’attester leur provenance. Résultat : un paquet applicatif léger, sûr et prêt à passer dans une chaîne de livraison moderne.
Écrire un Dockerfile durable
Fixez les versions des bases d’images, nettoyez les artefacts après build, passez en non-root à l’exécution et publiez des images multi-arch (amd64/arm64). Vous stabilisez vos déploiements et réduisez les surprises liées aux mises à jour système.
2. CI/CD : de l’idée au service en production, sans friction
La Continuous Integration (CI) transforme chaque commit en un événement de qualité. Le code est récupéré, compilé, testé et analysé automatiquement. Le pipeline devient un garde-fou : on refuse d’avancer si les tests cassent, si une dépendance est vulnérable ou si la couverture de code chute sous un seuil. La Continuous Delivery (CD) pousse ensuite ce même binaire dans des environnements représentatifs, où l’on peut valider manuellement les parcours critiques. Enfin, la Continuous Deployment automatise aussi le passage en production lorsque les garde-fous sont au vert. Dans tous les cas, l’essentiel n’est pas d’aller vite pour aller vite, mais de rendre le chemin répétable, observable et réversible.
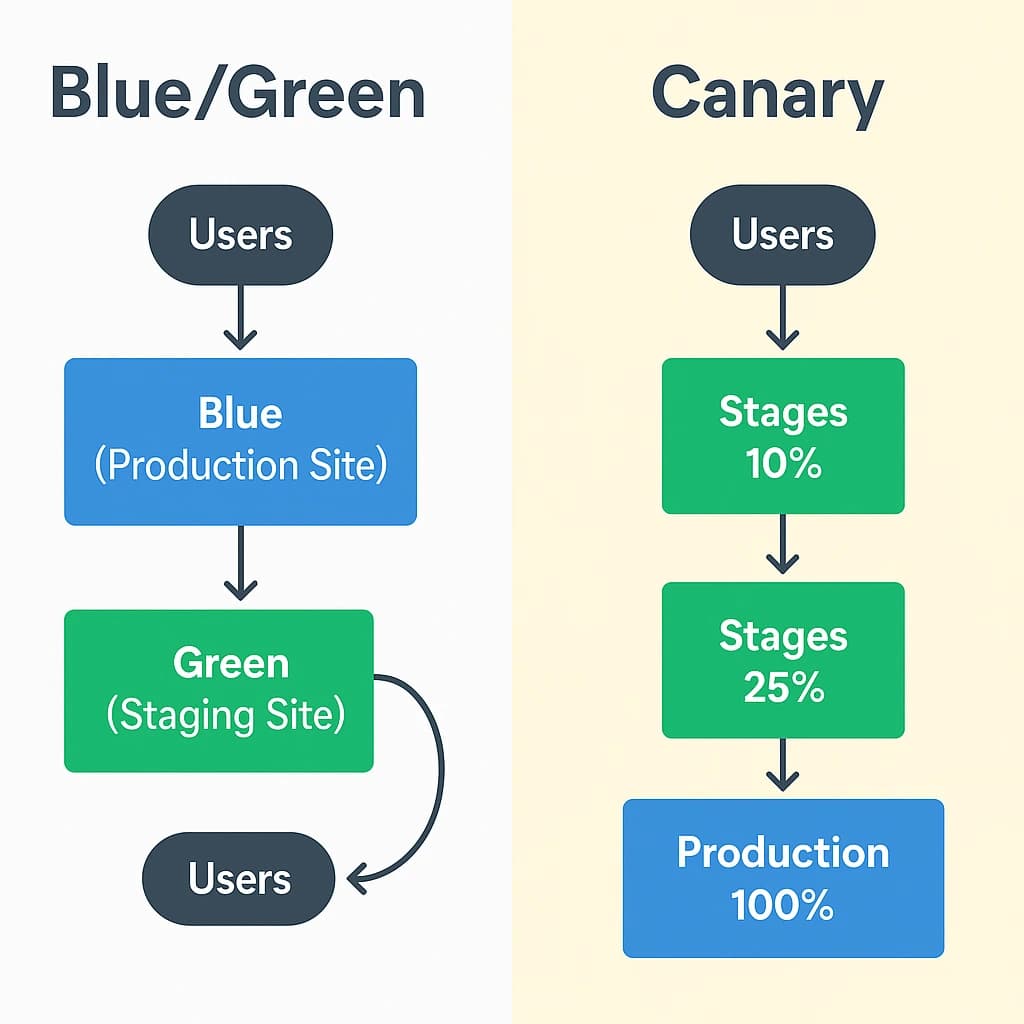
Les stratégies de déploiement modernes apportent une sérénité supplémentaire. Le blue/green maintient deux environnements jumeaux et bascule d’un simple interrupteur. Le canary expose la nouvelle version à un petit pourcentage d’utilisateurs, observe, puis élargit. Le rolling update remplace progressivement les instances en limitant l’impact perçu. Kubernetes excelle sur ces mécaniques, mais on peut déjà les simuler proprement avec un reverse-proxy et quelques règles de routage sur une architecture plus simple.
Dans les organisations 2025, le GitOps s’impose peu à peu comme modèle de référence. L’état désiré vit dans Git ; un agent compare en permanence ce qui est décrit à ce qui tourne réellement, puis réconcilie. On gagne une traçabilité native, un rollback trivial par git revert et un durcissement de la surface de déploiement, puisqu’on n’exécute plus de scripts ad hoc depuis des postes personnels.
GitOps = déclaratif, auditable et réversible. Ce n’est pas “un outil de plus”, c’est une façon plus sûre d’opérer.
Quels outils choisir en 2025 ?
Le marché s’est clarifié : GitHub Actions et GitLab CI couvrent l’immense majorité des besoins des PME avec des écosystèmes de runners et de templates très riches. Jenkins reste un couteau suisse historique, mais son coût de maintenance le réserve surtout à des cas particuliers. CircleCI séduit par sa simplicité cloud-first.
| Outil | Points forts | Limites |
|---|---|---|
| GitHub Actions | Intégration native GitHub, énorme Marketplace, secrets et OIDC bien intégrés. | Runners partagés parfois lents sur très gros builds. |
| GitLab CI/CD | Plateforme complète, GitOps natif, bonnes politiques de sécurité. | Demande un peu plus de mise en place côté runners. |
| Jenkins | Ultra-flexible, plugins innombrables, on-prem maîtrisé. | Dette technique et maintenance élevées si mal cadré. |
| CircleCI | Démarrage très rapide, pipelines lisibles, bon caching. | Coûts supérieurs au-delà d’un certain volume, écosystème plus restreint. |
Choisir son CI sans se tromper
Si votre code vit sur GitHub, commencez par Actions. Si vous êtes déjà sur GitLab, restez sur GitLab CI. Dans les deux cas, privilégiez des runners éphémères et le login cloud via OIDC plutôt que des clés longues durée.
3. Cas d’usage et résultats observés
Un SaaS B2B en croissance a remplacé ses scripts maison par un pipeline GitHub Actions : build multi-stage, tests, scan de sécurité, push en registre puis déploiement progressif sur Kubernetes. Avant, une mise en production prenait deux heures et générait un incident sur trois sprints. Après, la livraison passe en dix minutes, le retour arrière est automatique et l’équipe a regagné plus de 40 % de temps par sprint à consacrer au produit.
Dans l’e-commerce, la période des soldes est toujours un moment de vérité. En passant sur des conteneurs stateless derrière un rolling update avec contrôle de santé et seuils d’erreur, une enseigne a pu livrer deux optimisations de panier en plein pic sans interruption. La “magie” n’est pas technologique, elle est procédurale : on déploie plus petit, on mesure mieux et on revient en arrière en une commande si nécessaire.
Même les échecs deviennent instructifs lorsqu’ils sont cadrés. Une startup qui combinait un pipeline fragile et un monitoring minimal a provoqué un arrêt complet du service. La correction n’a pas été de « mieux croiser les doigts » mais d’ajouter des tests de bout en bout, d’intégrer des budgets d’erreur et de déclencher un rollback automatique si les métriques de conversion chutaient lors d’un canary.
Automatiser ne veut pas dire « débrancher le cerveau ». Cela veut dire poser des garde-fous : tests, métriques, alertes, et un plan de retour arrière simple.
4. Sécurité et conformité sans friction
La chaîne logicielle n’est solide que par ses maillons. En CI, on scanne le code (SAST), on exécute des tests dynamiques sur l’application (DAST) et on surveille les dépendances. Les images sont enrichies d’un SBOM pour lister précisément ce qu’elles contiennent. On les signe puis on atteste le build afin de pouvoir prouver la provenance d’un binaire. Ces informations suivent l’image jusqu’en production.
La gestion des secrets a, elle aussi, changé de paradigme. On n’expose plus de clés statiques dans des variables d’environnement ou des dépôts ; on délègue l’authentification au cloud via OIDC ou on stocke les secrets dans un coffre dédié. Côté conformité (RGPD, ISO 27001), les pipelines documentés et les journaux de déploiement apportent l’auditabilité qui manquait encore à beaucoup d’organisations.
Policy as code, sans douleur
Exprimez vos règles de sécurité et de déploiement sous forme de code (OPA/Gatekeeper, règles d’admission Kubernetes). Vous passez d’un contrôle humain fragile à des garde-fous automatiques.
5. Monitoring et observabilité : voir, décider, agir
Automatiser sans observer revient à conduire de nuit sans phares. Les métriques techniques (CPU, mémoire, erreurs), les logs structurés et les traces distribuées constituent un triptyque indispensable. Avec Prometheus et Grafana, vous visualisez les tendances et définissez des SLO réalistes ; avec Loki ou un équivalent, vous centralisez les logs ; avec OpenTelemetry, vous suivez un appel de bout en bout. L’objectif n’est pas la courbe parfaite, mais la décision rapide en cas d’anomalie : alerte, analyse, rollback.
6. Guide pas à pas (avec exemples concrets)
La mise en place ne se joue pas en un week-end, mais elle peut avancer par étapes nettes.
1) Dockeriser proprement l’application.
Commencez par un Dockerfile multi-stage, figez les versions, vérifiez que l’image démarre en non-root et publiez-la dans un registre privé.
FROM node:20-alpine AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
FROM node:20-alpine AS run
WORKDIR /app
ENV NODE_ENV=production
COPY package*.json ./
RUN npm ci --omit=dev
COPY /app/dist ./dist
USER node
EXPOSE 3000
CMD ["node","dist/server.js"]
2) Instaurer une CI utile (tests + qualité). À chaque push, exécutez les tests, produisez l’image, scannez-la puis poussez-la en registre.
name: ci
on: [push]
jobs:
build-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20 }
- run: npm ci && npm test
image:
needs: build-test
runs-on: ubuntu-latest
permissions:
id-token: write
contents: read
packages: write
steps:
- uses: actions/checkout@v4
- run: docker build -t ghcr.io/org/app:${{ github.sha }} .
- run: echo ${{ secrets.CR_PAT }} | docker login ghcr.io -u USER --password-stdin
- run: docker push ghcr.io/org/app:${{ github.sha }}
3) Déployer de manière contrôlée.
Sur un VPS, Compose suffit pour débuter. Sur Kubernetes, décrivez un Deployment et laissez l’orchestrateur faire un rolling update sous contrôle de santé. Pour des équipes matures, pilotez tout via GitOps.
4) Brancher l’observabilité et le rollback. Exposez des endpoints de santé, suivez les erreurs applicatives et les métriques business. Définissez un seuil qui déclenche un retour arrière automatique pendant un canary.
5) Durcir la chaîne logicielle. Générez un SBOM, signez et attestez vos images, remplacez les secrets statiques par OIDC et limitez les permissions des runners CI à ce qui est strictement nécessaire.
Exemple GitLab CI (pipeline compact)
stages: [test, build, deploy]
test:
stage: test
script:
- npm ci
- npm test
build:
stage: build
script:
- docker build -t registry.gitlab.com/group/app:$CI_COMMIT_SHA .
- docker push registry.gitlab.com/group/app:$CI_COMMIT_SHA
deploy:
stage: deploy
environment: production
script:
- kubectl set image deployment/app app=registry.gitlab.com/group/app:$CI_COMMIT_SHA
Jenkinsfile (si vous êtes déjà équipés)
pipeline {
agent any
stages {
stage('Test') { steps { sh 'npm ci && npm test' } }
stage('Build') { steps { sh 'docker build -t myrepo/app:$BUILD_NUMBER .' } }
stage('Push') { steps { sh 'docker push myrepo/app:$BUILD_NUMBER' } }
stage('Deploy') { steps { sh 'kubectl rollout restart deployment app' } }
}
}
Stratégies de déploiement : choisir selon le risque
| Stratégie | Principe | Avantages | Limites |
|---|---|---|---|
| Blue/Green | Deux environnements identiques, bascule instantanée. | Retour arrière immédiat, validation hors charge. | Coût temporaire plus élevé. |
| Canary | Exposition progressive à un pourcentage d’utilisateurs. | Risque maîtrisé, mesures concrètes. | Demande un monitoring fin. |
| Rolling | Remplacement progressif des instances. | Consommation de ressources limitée. | Retour arrière moins instantané. |
7. Pourquoi se faire accompagner
Mettre Docker et la CI/CD dans un contexte métier, c’est faire des choix d’architecture, pas cocher des cases techniques. L’enjeu n’est pas de “tout faire”, mais de choisir la bonne sophistication au bon moment : Compose ou Kubernetes, canary ou rolling, runners partagés ou dédiés, SBOM et signature selon votre niveau d’exigence. Un accompagnement réduit les boucles d’essai-erreur, documente le runbook et inscrit la démarche dans vos objectifs produits. C’est souvent la différence entre une usine à gaz et une chaîne de livraison sereine.
Docker, Kubernetes et CI/CD sont des multiplicateurs de vitesse. Mal cadrés, ils deviennent des multiplicateurs de dette technique. Le cadre fait la différence.
Conclusion
L’automatisation n’est pas une fin, c’est un moyen de concentrer l’énergie sur ce qui compte : livrer de la valeur à l’utilisateur. Avec Docker, vous standardisez l’exécution ; avec une CI/CD moderne, vous sécurisez le chemin ; avec des stratégies de déploiement adaptées, vous dédramatisez la mise en production. Les entreprises qui franchissent ce pas constatent le même triple effet : moins de stress, moins d’incidents, plus de vélocité.
« Un déploiement sans stress, c’est un business qui dort tranquille. » — Alexandre Bornand, AnalyWeb


